SEOMoz Guide Chapter 1: How Search Engines Operate

Search engines have two major functions – crawling & building an index, and providing answers by calculating relevancy & serving results.
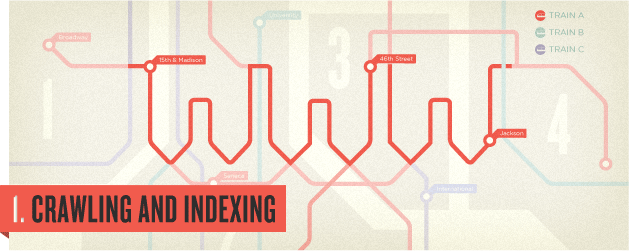
Imagine the World Wide Web as a network of stops in a big city subway system.
Each stop is its own unique document (usually a web page, but sometimes a PDF, JPG or other file). The search engines need a way to “crawl” the entire city and find all the stops along the way, so they use the best path available – links.
- Crawling and IndexingCrawling and indexing the billions of documents, pages, files, news, videos and media on the world wide web.
- Providing AnswersProviding answers to user queries, most frequently through lists of relevant pages, through retrieval and rankings.
“The link structure of the web serves to bind all of the pages together.”
Through links, search engines’ automated robots, called “crawlers,” or “spiders” can reach the many billions of interconnected documents.
Once the engines find these pages, they next decipher the code from them and store selected pieces in massive hard drives, to be recalled later when needed for a search query. To accomplish the monumental task of holding billions of pages that can be accessed in a fraction of a second, the search engines have constructed datacenters all over the world.
These monstrous storage facilities hold thousands of machines processing large quantities of information. After all, when a person performs a search at any of the major engines, they demand results instantaneously – even a 1 or 2 second delay can cause dissatisfaction, so the engines work hard to provide answers as fast as possible.

 Search engines are answer machines. When a person looks for something online, it requires the search engines to scour their corpus of billions of documents and do two things – first, return only those results that are relevant or useful to the searcher’s query, and second, rank those results in order of perceived usefulness. It is both “relevance” and “importance” that the process of SEO is meant to influence.
Search engines are answer machines. When a person looks for something online, it requires the search engines to scour their corpus of billions of documents and do two things – first, return only those results that are relevant or useful to the searcher’s query, and second, rank those results in order of perceived usefulness. It is both “relevance” and “importance” that the process of SEO is meant to influence.
To a search engine, relevance means more than simply finding a page with the right words. In the early days of the web, search engines didn’t go much further than this simplistic step, and their results suffered as a consequence. Thus, through evolution, smart engineers at the engines devised better ways to find valuable results that searchers would appreciate and enjoy. Today, 100s of factors influence relevance, many of which we’ll discuss throughout this guide.
How Do Search Engines Determine Importance?
Currently, the major engines typically interpret importance as popularity – the more popular a site, page or document, the more valuable the information contained therein must be. This assumption has proven fairly successful in practice, as the engines have continued to increase users’ satisfaction by using metrics that interpret popularity.
Popularity and relevance aren’t determined manually. Instead, the engines craft careful, mathematical equations – algorithms – to sort the wheat from the chaff and to then rank the wheat in order of tastiness (or however it is that farmers determine wheat’s value).
These algorithms are often comprised of hundreds of components. In the search marketing field, we often refer to them as “ranking factors” Moz crafted a resource specifically on this subject – Search Engine Ranking Factors.


You can surmise that search engines believe that Ohio State is the most relevant and popular page for the query “Universities” while the result, Harvard, is less relevant/popular.
or “How Search Marketers Succeed”
The complicated algorithms of search engines may appear at first glance to be impenetrable. The engines themselves provide little insight into how to achieve better results or garner more traffic. What information on optimization and best practices that the engines themselves do provide is listed below:


 Googlers recommend the following to get better rankings in their search engine:
Googlers recommend the following to get better rankings in their search engine:
- Make pages primarily for users, not for search engines. Don’t deceive your users or present different content to search engines than you display to users, which is commonly referred to as cloaking.
- Make a site with a clear hierarchy and text links. Every page should be reachable from at least one static text link.
- Create a useful, information-rich site, and write pages that clearly and accurately describe your content. Make sure that your <title> elements and ALT attributes are descriptive and accurate.
- Use keywords to create descriptive, human friendly URLs. Provide one version of a URL to reach a document, using 301 redirects or the rel=”canonical” element to address duplicate content.

Bing engineers at Microsoft recommend the following to get better rankings in their search engine:
- Ensure a clean, keyword rich URL structure is in place
- Make sure content is not buried inside rich media (Adobe Flash Player, JavaScript, Ajax) and verify that rich media doesn’t hide links from crawlers.
- Create keyword-rich content based on research to match what users are searching for. Produce fresh content regularly.
- Don’t put the text that you want indexed inside images. For example, if you want your company name or address to be indexed, make sure it is not displayed inside a company logo.
Over the 15 plus years that web search has existed, search marketers have found methods to extract information about how the search engines rank pages. SEOs and marketers use that data to help their sites and their clients achieve better positioning.
Surprisingly, the engines support many of these efforts, though the public visibility is frequently low. Conferences on search marketing, such as the Search Marketing Expo, Pubcon, Search Engine Strategies, Distilled & Moz’s own MozCon attract engineers and representatives from all of the major engines. Search representatives also assist webmasters by occasionally participating online in blogs, forums & groups.

There is perhaps no greater tool available to webmasters researching the activities of the engines than the freedom to use the search engines to perform experiments, test theories and form opinions. It is through this iterative, sometimes painstaking process, that a considerable amount of knowledge about the functions of the engines has been gleaned.
- Register a new website with nonsense keywords (e.g. ishkabibbell.com)
- Create multiple pages on that website, all targeting a similarly ludicrous term (e.g. yoogewgally)
- Test the use of different placement of text, formatting, use of keywords, link structures, etc by making the pages as uniform as possible with only a singular difference
- Point links at the domain from indexed, well-spidered pages on other domains
- Record the search engines’ activities and the rankings of the pages
- Make small alterations to the identically targeting pages to determine what factors might push a result up or down against its peers
- Record any results that appear to be effective and re-test on other domains or with other terms – if several tests consistently return the same results, chances are you’ve discovered a pattern that is used by the search engines.
In this test, we started with the hypothesis that a link higher up in a page’s code carries more weight than a page lower down in the code. We tested this by creating a nonsense domain linking out to three pages, all carrying the same nonsense word exactly once. After the engines spidered the pages, we found that the page linked to from the highest link on the home page ranked first.
This process is not alone in helping to educate search marketers.
Competitive intelligence about signals the engines might use and how they might order results is also available through patent applications made by the major engines to the United States Patent Office. Perhaps the most famous among these is the system that spawned Google’s genesis in the Stanford dormitories during the late 1990’s – PageRank – documented as Patent #6285999 – Method for node ranking in a linked database. The original paper on the subject – Anatomy of a Large-Scale Hypertextual Web Search Engine – has also been the subject of considerable study. To those whose comfort level with complex mathematics falls short, never fear. Although the actual equations can be academically interesting, complete understanding evades many of the most talented search marketers. Remedial calculus isn’t required to practice SEO!
Through methods like patent analysis, experiments, and live testing, search marketers as a community have come to understand many of the basic operations of search engines and the critical components of creating websites and pages that earn high rankings and significant traffic.
The rest of this guide is devoted to clearly explaining these practices. Enjoy!
Written by Rand Fishkin and Moz Staff
Source: http://moz.com/beginners-guide-to-seo/how-search-engines-operate